

Solving a VM-based CrackMe
Happy New Year! It’s been a while since I’ve posted anything here, as I’ve been quite occupied with a few other things – such as the Zero2Hero course that Vitali and I developed alongside SentinelOne, as well as migrating this site from one hosting provider to another, which caused a few issues but should all be fixed now!
Anyway, I’ve been wanting to post for a while now and recently came across MalwareTech’s VM1 challenge that I decided to have a go at. I personally find VM usage quite interesting, although very difficult to understand – for example the VM used in Pitou or FinSpy. Therefore, I decided to start off with a pretty simple challenge, so let’s get reversing!
If you want to attempt the challenge, you can grab it from here.
So, the description of the challenge reads:
vm1.exe implements a simple 8-bit virtual machine (VM) to try and stop reverse engineers from retrieving the flag. The VM’s RAM contains the encrypted flag and some bytecode to decrypt it. Can you figure out how the VM works and write your own to decrypt the flag? A copy of the VM’s RAM has been provided in ram.bin (this data is identical to the ram content of the malware’s VM before execution and contains both the custom assembly code and encrypted flag).
And the rules are:
You are not required to run vm1.exe, this challenge is static analysis only.
Do not use a debugger or dumper to retrieve the decrypted flag from memory, this is cheating.
Analysis can be done using the free version of IDA Pro (you don’t need the debugger).
In this case I’ll be using IDA Pro to analyze the binary, although tools such as Cutter or Ghidra will work just as well. I’ll also be scripting using Python3. Looking at the downloaded ZIP file, we have 2 files; vm1.exe and ram.bin, where ram.bin contains the bytecode and encrypted flag.
For those who aren’t aware of what a VM actually is in the context of malware/software packers, let me sum it up briefly; a Virtual Machine inside a sample is a method of obfuscating what the actual malware or packer is doing – for example a sample will have a large amount of bytecode inside of it that isn’t valid assembly, so it is impossible to analyze on its own. An interpreter will be built into the sample, which is responsible for taking the bytecode and executing it. The bytecode might be used in a switch case, where there is a large list of functions that have no cross references and are called through the bytecode, meaning an interpreter is required to understand how the sample works. An extremely common example of virtual machine implementations is Python – when executed, your script will be converted to bytecode, and the python interpreter is the only thing that can understand that bytecode and execute it. Here is a great post on writing a Python interpreter in Python if you’re interested!
Opening vm1.exe in IDA we can see a few API calls, some MD5 related function calls, and a call to sub_4022E0. First things first, I am interested in the memcpy() call, as it copies data from unk_404040 to a newly allocated region of memory, dword_40423C, which is then passed as an argument to MD5::DigestString(). So, let’s take a look at unk_404040 and see what we can see there.

Looking at the data in IDA, there seems to be 25 bytes of data after 30 null bytes, which is then followed by a lot more null bytes before reaching some more data at 0x40413F, which seems to have a similar structure every 3 bytes – at address 0x40413F there is 0x01, then 0x1D, and then 0xBD. After these first 3 bytes, there is 0x01, 0x05, 0x53, and then 0x01 again. After looking through the data a few more times, it seems that the first byte is either 0x01, 0x02, 0x03, or 0x04, with the rest of the data being seemingly random. At this point I am assuming that the data at unk_404040 is the bytecode – this becomes clear when we compare it to the data in ram.bin, which is identical.

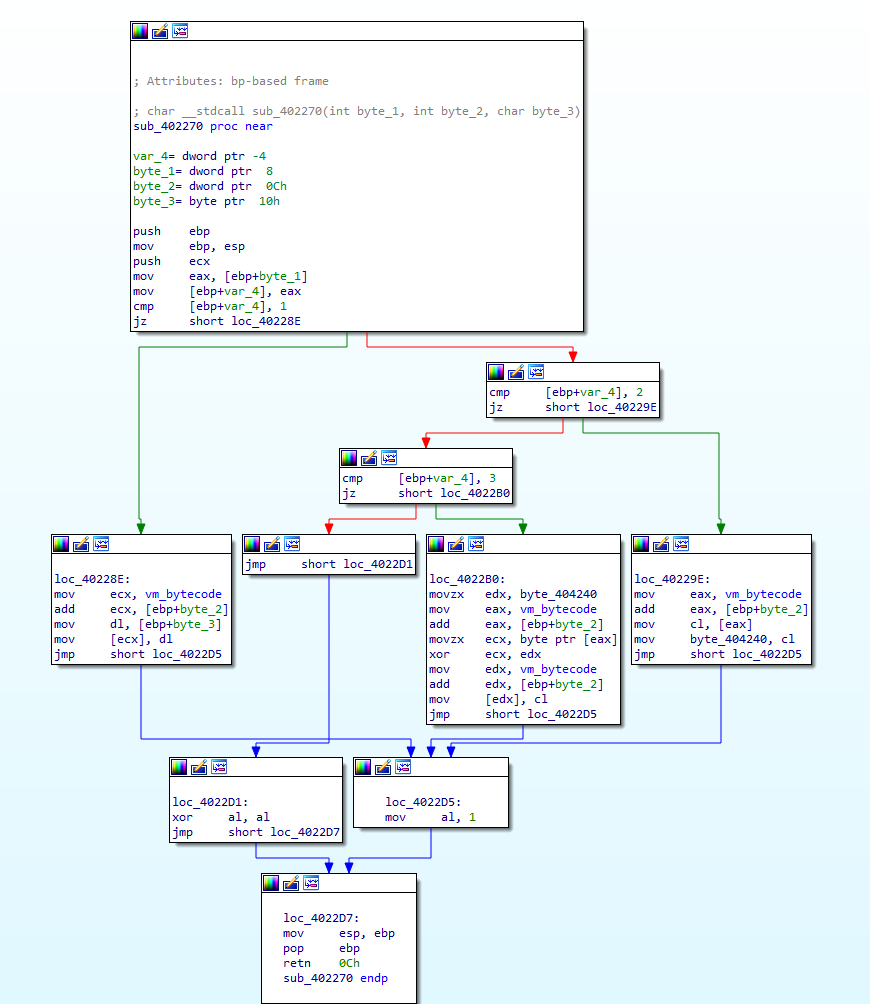
With the location of the bytecode now known, let’s take a look at the function sub_4022E0(). This function might look quite complex, but it is in fact fairly simple. First, var_1 is set to 0, and moved into ecx. The pointer to the VM Bytecode is moved into edx, and then one byte from [edx+ecx+0xFF] is moved into eax. Looking further down the block, we can see that var_1 is incremented by 3 each loop, so var_1 is obviously used as a counter in this case. Therefore, [edx+ecx+0xFF] is basically bytecode[counter+255], meaning the actual VM code begins at offset 255. Anyway, this first byte is moved into eax, which is then moved into var_10. var_1 is then incremented by 1, and moved into edx. The address of the VM bytecode is moved into eax, and a similar [eax+edx+0xFF] is used, except edx is now the counter and eax is the data. The byte is stored in ecx, which is moved into var_C. Once again, the counter var_1 is incremented by 1 and a similar action takes place, with the next byte being stored in var_8. var_1 is incremented for the final time in the loop, before var_8, var_C and var_10 are pushed as arguments to sub_402270(). The return value of this is tested, and then the function either returns or loops back around. With that analysed, we can already create pseudocode for what this function does:
counter = 0
while result:
byte_1 = bytecode[counter + 255]
counter += 1
byte_2 = bytecode[counter + 255]
counter += 1
byte_3 = bytecode[counter + 255]
counter += 1
decode_and_execute(byte_1, byte_2, byte_3) 
I’ve named the sub_402270() decode_and_execute() based on the fact that the bytecode is passed to it and that there are no other functions that handle the bytecode, so let’s take a look at how it works. First it’ll move byte_1 into var_4, which is used in a switch statement with the values 1, 2, 3, and 4. At this point, we can define byte_1 as the opcode as it determines the execution of the program, and byte_2 and byte_3 as operands (byte_2 = operand1, byte_3 = operand2).
If var_4 equals 1, the address of vm_bytecode is moved into ecx and is then added to the value in byte_2. byte_3 is moved into dl, which is then written to the memory region pointed to by ecx. The function then returns. The pseudocode for this function is very simple:
bytecode[operand1] = operand2Moving on, if var_4 equals 2, the address of vm_bytecode is moved into eax and is then added to the value in byte_2. The byte pointed to by this address is moved into cl, which is then moved into byte_404240. The function then returns. Once again, the pseudocode for this function is simple:
byte_404240 = bytecode[operand1]Finally, if var_4 equals 3, the value in byte_404240 is moved into edx, and the address of vm_bytecode is moved into eax, which is then added to the value in byte_2. The value pointed to this address is moved into ecx, which is XOR’d with the value in edx. This is then moved into vm_bytecode[byte_2]. Then, the function will return. The pseudocode for this block looks like:
vm_bytecode[operand1] ^= byte_404240If var_4 equals anything else, al is set to 0 before returning. For all the other blocks, al is set to 1.

So, now we know firstly the layout of the bytecode (opcode|operand1|operand2), and the functions that can be executed (mov, store, xor, exit), so now we can start scripting!
Scripting The Interpreter
Looking at the differences between the parser function and the functions that are executed based on the bytecode, it is clear there are 2 sections in the ram.bin file; the data section ([:255]) and the code section ([255:]). Therefore, I will be splitting the file into 2, to prevent any possible overwrite issues of either section. I’ll also be using classes to contain the code, so this will all be kept in the class VM(). Firstly we want to create the __init__() function, so let’s use that to initialize the vm_data and vm_instructions variables. Plus, we know that each bytecode instruction is 3 bytes long, so let’s split data[255:] into strings of 3 bytes in length and store that in a list. We can also set vm_data to be a bytearray, to make things a lot simpler during execution. We also initialize a variable xor_byte to 0, which is the byte_404240 we saw in IDA.

Next we need to create the actual functions executed based on the bytecode, so let’s take our pseudocode from earlier and put that into the script.
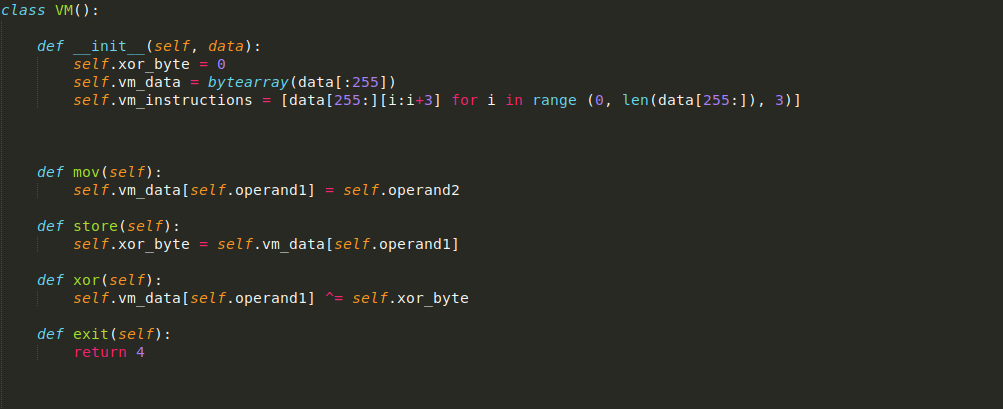
With the calls in place, now we just need to create a function that will parse the bytecode and call the function that corresponds to the opcode. While we can’t create an exact switch statement, we can use a dictionary, loop through each instruction, use the opcode to determine which function is executed, and make sure self.operand1 and self.operand2 are set before calling the VM function.

Finally, let’s add a main() function that will open ram.bin, read it, and pass the data onto the VM class, before it outputs the flag (splitting it using the delimiter “}” and adding it back to the string in an extremely pythonic way). After adding everything in, we are left with this final script:
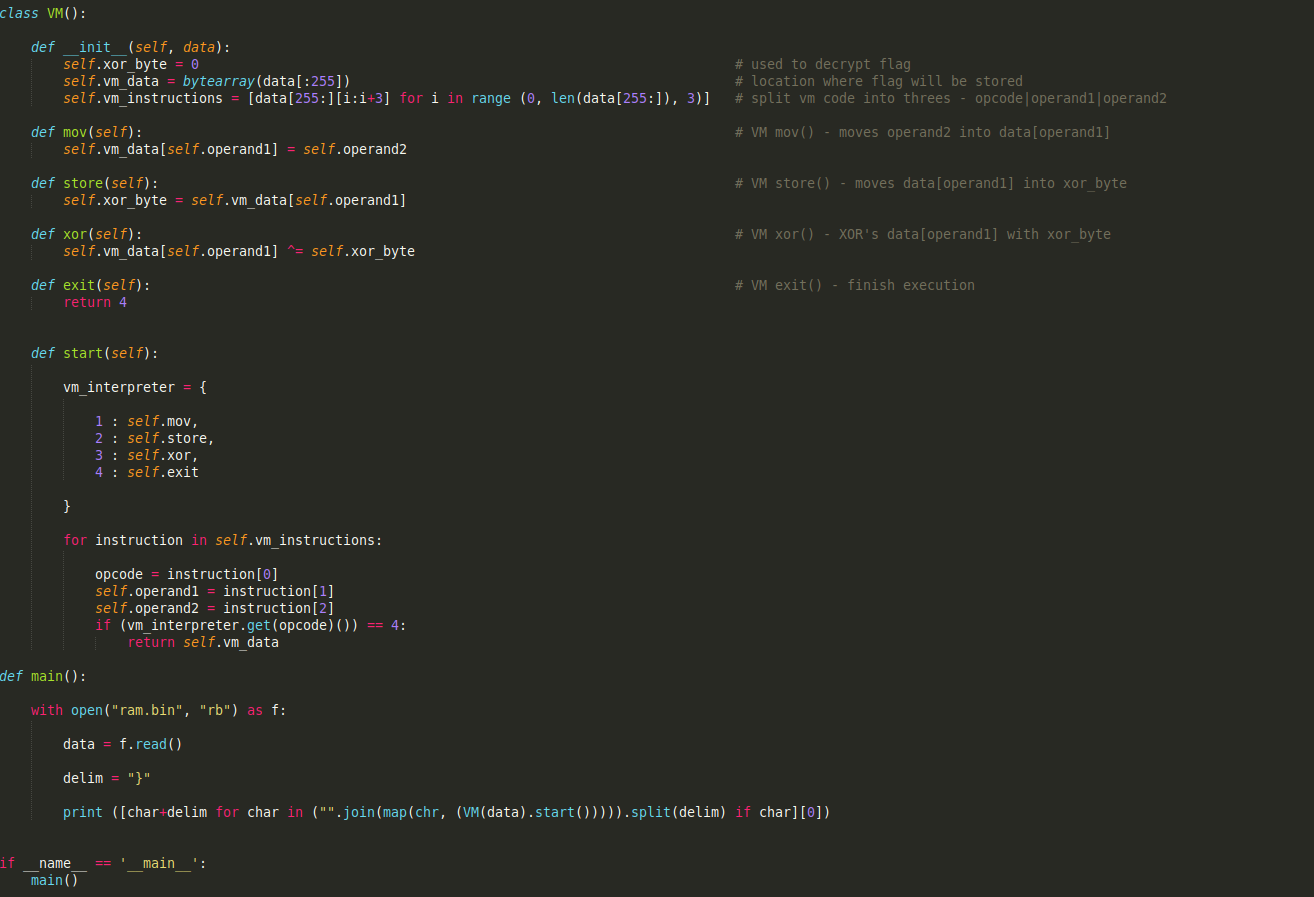
Executing the script will give the output:

And upon entering this into the flag checker, we get:

Hooray! We have the correct flag! However, at the moment we are getting the flag from a memory dump. What if we didn’t have the given memory dump and had to parse the main executable to first locate the address of the bytecode, and then dump it and parse? Well, let’s see if we can do that!
First things first, we need to write a YARA rule to detect and locate the memcpy() call which will point us to the VM bytecode. If this was a real sample of malware, this method would be pretty impractical as it relies on there being only one memcpy() call in the binary – and because YARA is only really used to detect malware samples, rather than find addresses, although it’s a good excuse to learn how YARA works!
Anyway, with that said, let’s start writing the rule mwt_vm_rule.yar. YARA searches samples for strings, hex patterns, and more based on given rules. We need to find the hex bytes of the call to memcpy() and use that to create a rule, so let’s quickly jump back to IDA and see what we’re dealing with.
So, looking at the function, the value 0x1FB is pushed, an offset is pushed, a dword is pushed, and then memcpy() is called. We want to get the offset in this case, but we can’t simply search for push offset 0x404040 as recompiling may change this offset, so instead of being 0x404040, it could be 0x404010, which would cause issues with YARA in terms of detecting the pattern. This is the same for the dword that is pushed, and the call to the address of memcpy(). Therefore, we have to use several wildcards in our rule. A wildcard is denoted as ??, which indicates that there could be any value in that place. As there are quite a few wildcards, it increases the chance of false positives. Therefore, we will use the size 0x1FB as a constant to keep false positives low.


As a result of this, our YARA rule (based on the hex view above), looks like this:
{A3 ?? ?? ?? ?? 68 FB 01 00 00 68 ?? ?? ?? ?? A1 ?? ?? ?? ?? 50 E8 ?? ?? ?? ??}Putting this into a .yar file, we now have the full rule:

Running this on the terminal using yara mwt_vm_rule.yar vm1.exe returns mwt_vm_rule vm1.exe – this means the rule worked and that byte pattern was located in the binary! Now we just have to port this over to Python3, parse the address from the full byte pattern, convert the virtual address to a file offset, and then extract the data! Let’s do that now.
Once again, we’re going to be using classes – this time class YARA(). For the __init__() function we’re going to accept the filename as an argument, and initialize the rule using yara.compile().

With that, we can create a find_rule() function, that uses YARA’s .match() function to search the binary for the byte pattern. We then parse what is returned for the actual byte match (which will contain the addresses we need) and return it – I put this in a try statement as the match may not exist in similar samples, and so we can handle the issue.

Executing this code (using binascii.hexlify() on the return value) so far will return this string of values, which I have split with | to show the important bytes:
A33c42400068fb010000|6840404000|a13c42400050e84a0000000x68 is the opcode for push, along with 404040 – this is the address of the VM bytecode. However, it is the virtual address of the bytecode – meaning it’s only useful when the program is mapped into memory. We’re dealing with a static binary here, so we need to convert this value to a file offset. To do that, we subtract the virtual address of the section it’s in from the address of the bytecode, and then add the pointer to raw data to that value. Therefore, the “equation” looks like this:
Address - VirtualAddress + PointerToRawDataThis is pretty simple to calculate, and we will be using pefile to do so. First, we subtract the base address of the image from the VM Bytecode address, which leaves us with 0x4040. Then we loop through each executable section until we find one which has a larger Virtual Address than the bytecode address. Once this is found, we take the Virtual Address and PointerToRawData from the previous section and break from the loop. Putting this together, we are left with the file offset 0x1E40, which we then return.

With that, let’s tie everything together with a “main” function, get_address(). This will call each function, and finally return the file offset to the calling function.

And now we have completed the class! Looking at the image below, you can see the entirety of the code.

We can also change up the main() function a bit, so now we call YARA(filename).get_address(data) and then seek the offset in the open file, read the bytecode, and then pass it onto the VM() class. And that’s all! We now can take the binary file, parse the bytecode from it, and interpret it! While the YARA isn’t extremely practical, my main goal was to showcase how it can be used and how to actually write basic rules based on functions, so I hope you learned something from it!

And on that note, I hope to have some more posts coming out soon, aimed at RE concepts and concepts applied to malware analysis, so stay tuned for that! And if you’re not already doing so, follow me on Twitter (@0verfl0w_) for updates on new posts or anything else RE/Malware Analysis related!
Comment (1)
Comments are closed.
TTS
10th January 2020Is this for all VM based systems (Microsoft, VMware, Oracle) or only one specific type of system?